Building a Rigorous Conversation Quality Evaluation System for Superhuman Go


Author: Arshi Jujara, Software Engineer at Superhuman.
What does it mean to have a quality conversation with a large language model (LLM) system?
At Superhuman, this question has been central to our work. We’re building a range of agentic and conversational features—including the AI assistant Superhuman Go and new Grammarly AI agents like Citation Finder—and as these products evolve, so do our users’ needs. To keep up, we need a clear definition of what “quality” looks like for these AI interactions, along with an evaluation system to measure conversations against that standard.
But evals are notoriously difficult to get right. LLMs are nondeterministic by design, which makes it difficult to establish a consistent evaluation framework. On top of that, quality is ultimately a human judgment: subjective, context-dependent, and hard to quantify.
In this blog post, we’ll describe how we developed a scalable, reliable eval system that still captures the nuances that matter in real human conversations. It draws on known techniques in the field (such as using an LLM as a judge) while applying insights from our decades of work with linguists and data scientists to build AI systems around the subtle art of communication.
Designing the system
Building any eval system starts by understanding what you’re trying to achieve. We had four main requirements:
- Scale: We wanted to rigorously evaluate a small sample of Superhuman Go conversations (~500) every day across multiple quality dimensions—a volume that quickly makes manual review impractical.
- Nuance: We wanted to assess the nuanced qualities of how helpful a conversation was to a user, including coherence, task completion, and ease of use.
- Privacy: Since we’re evaluating real human conversations, we needed to ensure we took appropriate measures to protect user data, such as de-identifying conversations for personally identifiable information (PII).
- Continuous: We wanted a system that could continuously provide teams with insights as they shipped products, both to monitor for regressions and to gain further insights into user trends and usage patterns to inform the product roadmap.
To meet these requirements, we would need to rely on both quantitative and qualitative metrics.
Quantitative metrics are traditional usage metrics that provide fast, clear signals on observable patterns, allowing product and data teams to quickly understand the impact of their changes. We track metrics across four categories:
- Conversation dynamics (e.g., turn count, message lengths)
- User behavior signals (e.g., repeated requests, user sentiment shifts across the conversation)
- User intent (e.g., classification of types of tasks users want assistance with)
- Agent stats (e.g., which agents are getting used the most)
Qualitative metrics are where LLM evals come into their own—capturing the nuance and context critical to quality conversations that automated metrics miss. We use an LLM as a judge to evaluate conversations, producing a score that reflects the overall quality and granular feedback on where the conversation falls short. Today, the judge runs as a daily job that evaluates a small sample of de-identified Superhuman Go conversations.
Underlying the LLM judge is human evaluation, which serves as the ground truth for the overall system. We run periodic evaluations to validate LLM judge ratings, catch edge cases, and calibrate new evaluation criteria.
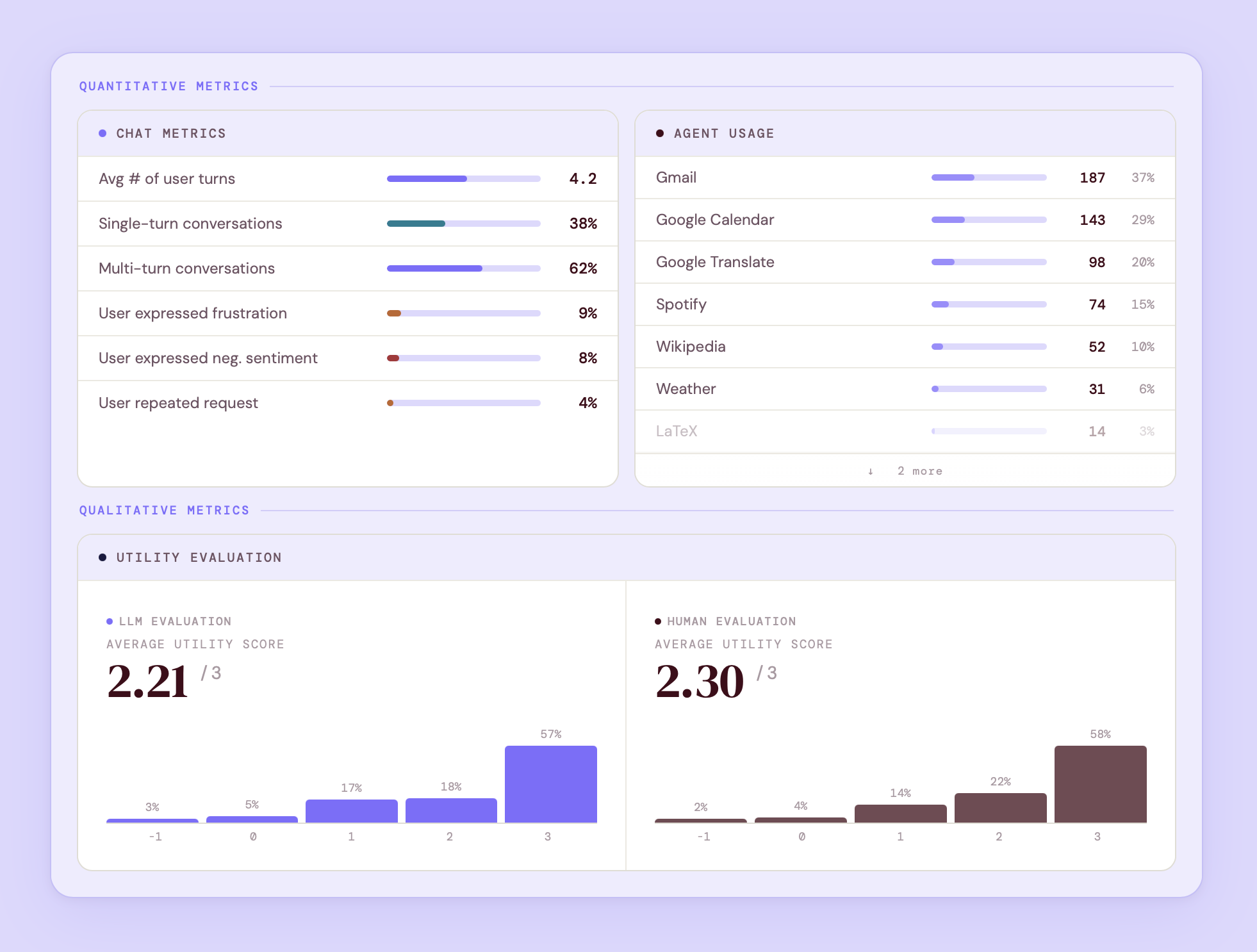
A sample output from our eval system that shows both quantitative and qualitative metrics (including a side-by-side of our LLM and human eval). All figures shown are for illustrative purposes and do not reflect actual production performance.
In the rest of this post, we’ll take a closer look at how we built our LLM judge—starting with understanding the elements of a quality conversation.
Creating a consistent definition of conversational quality
To build a reliable judge, we first needed a precise, shared definition of what “quality” actually means for an AI conversation, one grounded in real user behavior rather than abstract ideals.
To get there, we worked closely with our data science and linguistics teams to review a sample of de-identified Superhuman Go conversations to identify patterns. We looked for recurring failure patterns, places where we saw users lose trust in the system (even without an outright failure), and behaviors that consistently led to positive outcomes.
Based on our analysis, we came up with five core criteria of a quality conversation:
- Relevant: The assistant accurately interprets the user’s intent and stays focused on the task at hand, even across multiple turns.
- Context-aware: The assistant maintains and correctly applies context from earlier in the conversation. It can handle ambiguity, tone, and follow-ups in a way that feels natural to the conversation’s flow.
- Correctly formatted: The assistant structures responses appropriately for the given request (e.g., email format for email drafts, lists for summaries).
- Accurate: The assistant provides accurate, complete, and reliable information (i.e., no hallucinations).
- Proper execution: When asked to take action, the assistant performs only those actions it can reliably perform correctly and consistently.
Translating quality into a measurable score
We initially scored conversations on a binary scale—“good” and “bad”—based on whether the model met all five criteria. But this approach didn’t provide teams with enough granularity. For instance, a conversation where an agent partially completed a requested action isn’t a total pass (the agent didn’t complete all requested actions), but neither is it a clear fail either (since it did deliver some value).
That’s why we shifted to a utility rating scale that measures the value the conversation delivered to the user:
- Negative (-1): Conversation actively misled or frustrated the user.
- Neutral (0): Conversation wasn’t useful but didn’t mislead.
- Small (1): Saved some effort but didn’t fully accomplish the goal.
- Large (2): Definitely useful; accomplished almost everything needed.
- Exceptional (3): Did exactly what the user wanted; saved significant effort.
In addition to this score, the system can flag which quality conversation criteria had room for improvement, adding a diagnostic layer that gives teams more context behind a rating.
Here’s how the scoring process works in practice. A conversation in which an agent partially completed a request but didn’t hallucinate would score a 1—it delivered some value, just not the full picture, thereby falling short on the proper execution and relevance criteria. But if the agent hallucinated the entire output, that scores a -1—the conversation actively misled the user, which is a clear miss of the accuracy criteria.
Building the LLM-as-a-judge
Armed with our conversation evaluation framework, we had everything we needed to create the initial judge prompt. The harder challenge was knowing when it was accurate enough to deploy to production. Three principles guided our approach:
- Your judge is only as good as your human-annotated data. Reliable human-annotated data is key to creating reliable gold-standard datasets (goldsets). Fortunately, Grammarly has spent decades developing guidelines, onboarding, and training for accurate human annotation—a foundation we leveraged to create the goldsets for the judge.
- Treat the process like writing code, not configurations. A judge prompt isn’t something you write once and ship. We manually compared outputs against our goldset and debugged continuously, the same way we fix code until all tests pass.
- Reliability requires ongoing evaluation. Deploying the judge isn’t the finish line. To ensure the judge evolves with shifting product and user needs, we needed to invest in regular spot-checks and recalibration cycles.
Just like with code, iterating on the judge was anything but linear. Early versions had significant gaps—for example, they hyperfocused on minor formatting issues while missing more meaningful failures.
The root cause was the “lost-in-the-middle” effect, in which the model struggles to act on or focus on information in the middle of a long prompt. Solving this challenge required systematic prompt engineering, with adjustments such as:
- Consolidating the entire chat response into a single JSON field significantly improved the judge’s ability to process it correctly.
- Reiterating the critical evaluation criteria at multiple points in the prompt (rather than stating them once) to counteract the lost-in-the-middle effect.
- Introducing an intermediate step in our scoring by asking the judge to produce a more detailed score internally and then map it to our utility scale (rather than asking it to map to the scale directly).
Together, these refinements brought the judge’s evaluations close enough to our human annotator goldset that we were confident deploying it to production.
Our eval system in action
The eval system is live today, helping Superhuman product teams proactively understand usage patterns, measure the impact of product changes, and catch emerging issues before they escalate.
For example, we’re constantly tweaking the underlying models that power Superhuman Go, and our eval system helps us quickly understand the impact of these changes. Quantitative metrics give us a read on overall performance: for example, how a change affects task completion rates or whether it’s causing an uptick in conversation turns. Judge scores add color to those numbers, helping us understand the why: Is the new model producing more relevant responses? Is it better at picking up on context? Together, they’ve compressed our feedback loops from weeks to days, so we can catch and fix issues long before they show up in Support tickets or churn.
We’re proud of the work we’ve done, but we’re still very early in the process. If you’re excited about building eval systems that make AI products more measurable, come join us. Check out our Careers page.
